What Is Machine Learning? MATLAB & Simulink

ML applications learn from experience (or to be accurate, data) like humans do without direct programming. When exposed to new data, these applications learn, grow, change, and develop by themselves. In other words, machine learning involves computers finding insightful information without being told where to look. Instead, they do this by leveraging algorithms that how does machine learning algorithms work learn from data in an iterative process. Machine Learning is a subset of Artificial Intelligence that uses datasets to gain insights from it and predict future values. It uses a systematic approach to achieve its goal going through various steps such as data collection, preprocessing, modeling, training, tuning, evaluation, visualization, and model deployment.
Many algorithms have been proposed to reduce data dimensions in the machine learning and data science literature [41, 125]. The goal of SVM is to find the best possible decision boundary by maximizing the margin between the two sets of labeled data. Any new data point that falls on either side of this decision boundary is classified based on the labels in the training dataset. Clustering algorithms are particularly useful for large datasets and can provide insights into the inherent structure of the data by grouping similar points together. It has applications in various fields such as customer segmentation, image compression, and anomaly detection.
- Deep learning models tend to increase their accuracy with the increasing amount of training data, whereas traditional machine learning models such as SVM and naive Bayes classifier stop improving after a saturation point.
- In simple terms, a machine learning algorithm is like a recipe that allows computers to learn and make predictions from data.
- This is achieved by creating a range for binary classification, such as any output between 0-.49 is put in one group, and any between .50 and 1.00 is put in another.
- Training data being known or unknown data to develop the final Machine Learning algorithm.
- This program gives you in-depth and practical knowledge on the use of machine learning in real world cases.
Reinforcement learning is often used to create algorithms that must effectively make sequences of decisions or actions to achieve their aims, such as playing a game or summarizing an entire text. In this article, you’ll learn more about what machine learning is, including how it works, different types of it, and how it’s actually used in the real world. We’ll take a look at the benefits and dangers that machine learning poses, and in the end, you’ll find some cost-effective, flexible courses that can help you learn even more about machine learning. Originating from statistics, linear regression performs a regression task, which maps a constant slope using an input value (X) with a variable output (Y) to predict a numeric value or quantity. Gradient Boosting Machine is like a team of little learners that work together to solve a big problem. Each learner starts with some basic knowledge and tries to improve by focusing on the mistakes made by the previous learners.
What are some examples of machine learning?
In other words, the algorithms are fed data that includes an “answer key” describing how the data should be interpreted. For example, an algorithm may be fed images of flowers that include tags for each flower type so that it will be able to identify the flower better again when fed a new photograph. A supervised learning algorithm uses a labelled data set to train an algorithm, effectively guaranteeing that it has an answer key available to cross-reference predictions and refine its system. As a result, supervised learning is best suited to algorithms faced with a specific outcome in mind, such as classifying images. At its core, Machine Learning involves training a model to make predictions or decisions based on patterns and relationships in data. To understand the fundamentals of Machine Learning, it is essential to grasp key concepts such as features, labels, training data, and model optimization.

Machine learning works to show the relationship between the two, then the relationships are placed on an X/Y axis, with a straight line running through them to predict future relationships. Machine learning is an expansive field and there are billions of algorithms to choose from. Let’s dive into different kinds of machine learning and the most-used algorithms to get an idea of how machine learning works. Reinforcement learning works by programming an algorithm with a distinct goal and a prescribed set of rules for accomplishing that goal. To help you get a better idea of how these types differ from one another, here’s an overview of the four different types of machine learning primarily in use today.
Machine Learning: Algorithms, Real-World Applications and Research Directions
Tree-based algorithms are a fundamental component of machine learning, offering intuitive decision-making processes akin to human reasoning. These algorithms construct decision trees, where each branch represents a decision based on features, ultimately leading to a prediction or classification. By recursively partitioning the feature space, tree-based algorithms provide transparent and interpretable models, making them widely utilized in various applications. In this article, we going to learn the fundamentals of tree based algorithms.
The selection of an algorithm, on the other hand, should be based on testing and evaluation of the specific problem and dataset at hand. Machine learning algorithms have the potential to transform industries and improve our daily lives, but they also raise important ethical considerations and challenges. In this article, we’ll explore some of the key ethical implications of machine learning algorithms and the challenges that arise from their use.
At each branch, you make a choice based on certain conditions, and eventually, you reach a conclusion at the end of a branch. Decision trees are commonly used in various fields, such as business, education, and medicine, to help people make choices and solve problems. Use regression techniques if you are working with a data range or if the nature of your response is a real number, such as temperature or the time until failure for a piece of equipment. Let’s say the initial weight value of this neural network is 5 and the input x is 2. Therefore the prediction y of this network has a value of 10, while the label y_hat might have a value of 6.
Deep learning is a type of machine learning and artificial intelligence that uses neural network algorithms to analyze data and solve complex problems. Neural networks in deep learning are comprised of multiple layers of artificial nodes and neurons, which help process information. During the training process, this neural network optimizes this step to obtain the best possible abstract representation of the input data. This means that deep learning models require little to no manual effort to perform and optimize the feature extraction process.
Semi-supervised learning is just what it sounds like, a combination of supervised and unsupervised. It uses a small set of sorted or tagged training data and a large set of untagged data. The models are guided to perform a specific calculation or reach a desired result, but they must do more of the learning and data organization themselves, as they’ve only been given small sets of training data. Machine learning (ML) is a type of artificial intelligence (AI) focused on building computer systems that learn from data.
AI vs. machine learning vs. deep learning: Key differences – TechTarget
AI vs. machine learning vs. deep learning: Key differences.
Posted: Tue, 14 Nov 2023 08:00:00 GMT [source]
The objective is to find the best set of parameters for the model that minimizes the prediction errors or maximizes the accuracy. This is typically done through an iterative process called optimization or training, where the model’s parameters are adjusted based on the discrepancy between its predictions and the actual labels in the training data. Machine learning is often used to solve problems that are too complex or time-consuming for humans to solve manually, such as analysing large amounts of data or detecting patterns in data that are not immediately apparent.
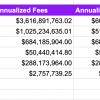
In the current age of the Fourth Industrial Revolution (4IR), machine learning becomes popular in various application areas, because of its learning capabilities from the past and making intelligent decisions. In the following, we summarize and discuss ten popular application areas of machine learning technology. Machine learning (ML) can do everything from analyzing X-rays to predicting stock market prices to recommending binge-worthy television shows. With such a wide range of applications, it’s not surprising that the global machine learning market is projected to grow from $21.7 billion in 2022 to $209.91 billion by 2029, according to Fortune Business Insights [1]. Amid the enthusiasm, companies will face many of the same challenges presented by previous cutting-edge, fast-evolving technologies. New challenges include adapting legacy infrastructure to machine learning systems, mitigating ML bias and figuring out how to best use these awesome new powers of AI to generate profits for enterprises, in spite of the costs.
How do Big Data and AI Work Together? – TechTarget
How do Big Data and AI Work Together?.
Posted: Thu, 21 Dec 2023 08:00:00 GMT [source]
K-Means clustering is an unsupervised learning approach that can be used to group together data points. It works by finding k clusters in the data so that the data points in each cluster are as similar to each other as feasible while remaining as distinct as possible from the data points in other clusters. Decision trees are a type of supervised learning technique that can be used for classification as well as regression.
Generally, during semi-supervised machine learning, algorithms are first fed a small amount of labeled data to help direct their development and then fed much larger quantities of unlabeled data to complete the model. For example, an algorithm may be fed a smaller quantity of labeled speech data and then trained on a much larger set of unlabeled speech data in order to create a machine learning model capable of speech recognition. Machine learning refers to the general use of algorithms and data to create autonomous or semi-autonomous machines. Deep learning, meanwhile, is a subset of machine learning that layers algorithms into “neural networks” that somewhat resemble the human brain so that machines can perform increasingly complex tasks. When an artificial neural network learns, the weights between neurons change, as does the strength of the connection.

Many classification algorithms have been proposed in the machine learning and data science literature [41, 125]. In the following, we summarize the most common and popular methods that are used widely in various application areas. K-means is an unsupervised algorithm commonly used for clustering and pattern recognition tasks.
Careers in machine learning and AI
Among the association rule learning techniques discussed above, Apriori [8] is the most widely used algorithm for discovering association rules from a given dataset [133]. The main strength of the association learning technique is its comprehensiveness, as it generates all associations that satisfy the user-specified constraints, such as minimum support and confidence value. The ABC-RuleMiner approach [104] discussed earlier could give significant results in terms of non-redundant rule generation and intelligent decision-making for the relevant application areas in the real world. Association rule learning is a rule-based machine learning approach to discover interesting relationships, “IF-THEN” statements, in large datasets between variables [7]. One example is that “if a customer buys a computer or laptop (an item), s/he is likely to also buy anti-virus software (another item) at the same time”. Association rules are employed today in many application areas, including IoT services, medical diagnosis, usage behavior analytics, web usage mining, smartphone applications, cybersecurity applications, and bioinformatics.
Additionally, the processes for utilising these tools are illustrated in this paper. The features are extracted like packet size, packet byes, source address, destination address, length, and corresponding protocols. Feature extraction requires a significant amount of domain expertise and manual work from professionals in current machine learning-based botnet detection systems. Botnets are divided based on their protocol, such as Internet relay chat, DNS, and P2P which are used by the C&C Server. Long before we began using deep learning, we relied on traditional machine learning methods including decision trees, SVM, naïve Bayes classifier and logistic regression.
During training, these weights adjust; some neurons become more connected while some neurons become less connected. Accordingly, the values of z, h and the final output vector y are changing with the weights. Some weights make the predictions of a neural network closer to the actual ground truth vector y_hat; other weights increase the distance to the ground truth vector.
Supervised learning
Machine learning operations (MLOps) is the discipline of Artificial Intelligence model delivery. It helps organizations scale production capacity to produce faster results, thereby generating vital business value. In this case, the unknown data consists of apples and pears which look similar to each other. The trained model tries to put them all together so that you get the same things in similar groups.

For a refresh on the above-mentioned prerequisites, the Simplilearn YouTube channel provides succinct and detailed overviews. Now that you know what machine learning is, its types, and its importance, let us move on to the uses of machine learning. In this case, the model tries to figure out whether the data is an apple or another fruit.
Much like KNN, K-Means uses the proximity of an output to a cluster of data points to identify it. Each of the clusters is defined by a centroid, a real or imaginary centre point for the cluster. K-Means is useful on large data sets, especially for clustering, though it can falter when handling outliers. K-Means is an unsupervised algorithm used for classification and predictive modelling.
Deep learning is just a type of machine learning, inspired by the structure of the human brain. Deep learning algorithms attempt to draw similar conclusions as humans would by continually analyzing data with a given logical structure. To achieve this, deep learning uses multi-layered structures of algorithms called neural networks.
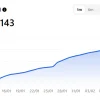
The x-axis of the figure indicates the specific dates and the corresponding popularity score within the range of \(0 \; (minimum)\) to \(100 \; (maximum)\) has been shown in y-axis. 1, the popularity indication values for these learning types are low in 2015 and are increasing day by day. These statistics motivate us to study on machine learning in this paper, which can play an important role in the real-world through Industry 4.0 automation. In the following section, we discuss several application areas based on machine learning algorithms. Deep learning is a specific application of the advanced functions provided by machine learning algorithms.
- Although each of these factors is considered independently, the algorithm combines them to assess the probability of an object being a particular plant.
- Much like how a child learns, the algorithm slowly begins to acquire an understanding of its environment and begins to optimize actions to achieve particular outcomes.
- New input data is fed into the machine learning algorithm to test whether the algorithm works correctly.
- The latter, AI, refers to any computer system that can perform tasks that typically require human intelligence, such as perception, reasoning, learning, and decision-making.
Supervised machine learning builds a model that makes predictions based on evidence in the presence of uncertainty. A supervised learning algorithm takes a known set of input data and known responses to the data (output) and trains a model to generate reasonable predictions for the response to new data. Use supervised learning if you have known data for the output you are trying to predict. In the area of machine learning and data science, researchers use various widely used datasets for different purposes. The data can be in different types discussed above, which may vary from application to application in the real world.
The features are then used to create a model that categorizes the objects in the image. With a deep learning workflow, relevant features are automatically extracted from images. In addition, deep learning performs “end-to-end learning” – where a network is given raw data and a task to perform, such as classification, and it learns how to do this automatically. That is, in machine learning, a programmer must intervene directly in the action for the model to come to a conclusion. A new industrial revolution is taking place, driven by artificial neural networks and deep learning. At the end of the day, deep learning is the best and most obvious approach to real machine intelligence we’ve ever had.

Once trained, the random forest takes the same data and feeds it into each decision tree. The most common prediction among all the decision trees is then selected as the final prediction for the dataset. You can foun additiona information about ai customer service and artificial intelligence and NLP. Logistic regression, also known as “logit regression,” is a supervised learning algorithm primarily used for binary classification tasks. It is commonly employed when we want to determine whether an input belongs to one class or another, such as deciding whether an image is a cat or not a cat. In simple terms, a machine learning algorithm is like a recipe that allows computers to learn and make predictions from data.
Semi-supervised learning is often used to categorise large amounts of unlabelled data because it might be unfeasible or too difficult to label all the data. Linear regression is a supervised learning algorithm used to predict and forecast values within a continuous range, such as sales numbers or prices. In this tutorial, we have explored the fundamental concepts and processes of Machine Learning. We also learned how Machine Learning enables computers to learn from data and make predictions or decisions without explicit programming.
Now that we understand the neural network architecture better, we can better study the learning process. For a given input feature vector x, the neural network calculates a prediction vector, which we call h. The analogy to deep learning is that the rocket engine is the deep learning models and the fuel is the huge amounts of data we can feed to these algorithms. If the prediction and results don’t match, the algorithm is re-trained multiple times until the data scientist gets the desired outcome. This enables the machine learning algorithm to continually learn on its own and produce the optimal answer, gradually increasing in accuracy over time. For starters, machine learning is a core sub-area of Artificial Intelligence (AI).
Choosing the right algorithm for a task calls for a strong grasp of mathematics and statistics. Training machine learning algorithms often involves large amounts of good quality data to produce accurate results. The results themselves can be difficult to understand — particularly the outcomes produced by complex algorithms, such as the deep learning neural networks patterned after the human brain. Supervised learning is a type of machine learning algorithms where we used labeled dataset to train the model or algorithms.
That’s especially true in industries that have heavy compliance burdens, such as banking and insurance. Data scientists often find themselves having to strike a balance between transparency and the accuracy and effectiveness of a model. Complex models can produce accurate predictions, but explaining to a layperson — or even an expert — how an output was determined can be difficult. Semi-supervised machine learning uses both unlabeled and labeled data sets to train algorithms.
It’s the number of node layers, or depth, of neural networks that distinguishes a single neural network from a deep learning algorithm, which must have more than three. In Table 1, we summarize various types of machine learning techniques with examples. In the following, we provide a comprehensive view of machine learning algorithms that can be applied to enhance the intelligence and capabilities of a data-driven application. A support vector machine (SVM) is a supervised learning algorithm commonly used for classification and predictive modeling tasks. SVM algorithms are popular because they are reliable and can work well even with a small amount of data.
The most common result is then selected as the most likely outcome for the data set. A machine learning algorithm is a set of rules or processes used by an AI system to conduct tasks—most often to discover new data insights and patterns, or to predict output values from a given set of input variables. Training data is a collection of labelled examples for training a Machine Learning model. During the training phase, the model learns the underlying patterns in the data by adjusting its internal parameters. The model’s performance is evaluated using a separate data set called the test set, which contains examples not used during training. However, neural networks, which mimic how the neurons in the brain work, are pretty popular today.
Overall, traditional programming is a more fixed approach where the programmer designs the solution explicitly, while ML is a more flexible and adaptive approach where the ML model learns from data to generate a solution. In traditional programming, a programmer manually provides specific instructions to the computer based on their understanding and analysis of the problem. If the data or the problem changes, the programmer needs to manually update the code. Traditional programming and machine learning are essentially different approaches to problem-solving.
Based on the majority of the labels among the K nearest neighbors, the algorithm assigns a classification to the new data point. For instance, if most of the nearest neighbors are blue points, the algorithm classifies the new point as belonging to the blue group. Let’s consider a program that identifies plants using a Naive Bayes algorithm. The algorithm takes into account specific factors such as perceived size, color, and shape to categorize images of plants. Although each of these factors is considered independently, the algorithm combines them to assess the probability of an object being a particular plant. K-means is an iterative algorithm that uses clustering to partition data into non-overlapping subgroups, where each data point is unique to one group.